A Review Of Printable DOP-C01 Free Practice Test
It is more faster and easier to pass the Amazon-Web-Services DOP-C01 exam by using Highest Quality Amazon-Web-Services AWS Certified DevOps Engineer- Professional questuins and answers. Immediate access to the Renovate DOP-C01 Exam and find the same core area DOP-C01 questions with professionally verified answers, then PASS your exam with a high score now.
Free demo questions for Amazon-Web-Services DOP-C01 Exam Dumps Below:
NEW QUESTION 1
Your application uses Amazon SQS and Auto Scaling to process background jobs. The Auto Scaling policy is based on the number of messages in the queue, with a maximum instance count of 100. Since the application was launched, the group has never scaled above 50. The Auto scaling group has now scaled to 100, the queue size is increasing and very few jobs are being completed. The number of messages being sent to the queue is at normal levels. What should you do to identity why the queue size is unusually high and to reduce it?
- A. Temporarily increase the AutoScaling group's desired value to 200. When the queue size has been reduced,reduce it to 50.
- B. Analyzethe application logs to identify possible reasons for message processingfailure and resolve the cause for failure
- C. V
- D. Createadditional Auto Scalinggroups enabling the processing of the queue to beperformed in parallel.
- E. AnalyzeCloudTrail logs for Amazon SQS to ensure that the instances Amazon EC2 role haspermission to receive messages from the queue.
Answer: B
Explanation:
Here the best option is to look at the application logs and resolve the failure. You could be having a functionality issue in the application that is causing the messages to queue up and increase the fleet of instances in the Autoscaling group.
For more information on centralized logging system implementation in AWS, please visit this link: https://aws.amazon.com/answers/logging/centralized-logging/
NEW QUESTION 2
You need to run a very large batch data processingjob one time per day. The source data exists
entirely in S3, and the output of the processingjob should also be written to S3 when finished. If you need to version control this processingjob and all setup and teardown logic for the system, what approach should you use?.
- A. Model an AWSEMRjob in AWS Elastic Beanstalk.
- B. Model an AWSEMRjob in AWS CloudFormation.
- C. Model an AWS EMRjob in AWS OpsWorks.
- D. Model an AWS EMRjob in AWS CLI Composer.
Answer: B
Explanation:
With AWS Cloud Formation, you can update the properties for resources in your existing stacks.
These changes can range from simple configuration changes, such
as updating the alarm threshold on a Cloud Watch alarm, to more complex changes, such as updating the Amazon Machine Image (AMI) running on an Amazon EC2
instance. Many of the AWS resources in a template can be updated, and we continue to add support for more.
For more information on Cloudformation version control, please visit the below URL: http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/updating.stacks.wa I kthrough.htm I
NEW QUESTION 3
Management has reported an increase in the monthly bill from Amazon Web Services, and they are extremely concerned with this increased cost. Management has asked you to determine the exact cause of this increase. After reviewing the billing report, you notice an increase in the data transfer cost. How can you provide management with a better insight into data transfer use?
- A. Update your Amazon CloudWatch metrics to use five-second granularity, which will give better detailed metrics that can be combined with your billing data to pinpoint anomalies.
- B. Use Amazon CloudWatch Logs to run a map-reduce on your logs to determine high usage and data transfer.
- C. Deliver custom metrics to Amazon CloudWatch per application that breaks down application data transfer into multiple, more specific data points.D- Using Amazon CloudWatch metrics, pull your Elastic Load Balancing outbound data transfer metrics monthly, and include them with your billing report to show which application is causing higher bandwidth usage.
Answer: C
Explanation:
You can publish your own metrics to CloudWatch using the AWS CLI or an API. You can view statistical graphs of your published metrics with the AWS Management Console.
CloudWatch stores data about a metric as a series of data points. Each data point has an associated time stamp. You can even publish an aggregated set of data points called a statistic set.
If you have custom metrics specific to your application, you can give a breakdown to the management on the exact issue.
Option A won't be sufficient to provide better insights.
Option B is an overhead when you can make the application publish custom metrics Option D is invalid because just the ELB metrics will not give the entire picture
For more information on custom metrics, please refer to the below document link: from AWS http://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.htmI
NEW QUESTION 4
A gaming company adopted AWS Cloud Formation to automate load-testing of theirgames. They have created an AWS Cloud Formation template for each gaming environment and one for the load- testing stack. The load-testing stack creates an Amazon Relational Database Service (RDS) Postgres database and two web servers running on Amazon Elastic Compute Cloud (EC2) that send HTTP requests, measure response times, and write the results into the database. A test run usually takes between 15 and 30 minutes. Once the tests are done, the AWS Cloud Formation stacks are torn down immediately. The test results written to the Amazon RDS database must remain accessible for visualization and analysis.
Select possible solutions that allow access to the test results after the AWS Cloud Formation load - testing stack is deleted.
Choose 2 answers.
- A. Define an Amazon RDS Read-Replica in theload-testing AWS Cloud Formation stack and define a dependency relation betweenmaster and replica via the Depends On attribute.
- B. Define an update policy to prevent deletionof the Amazon RDS database after the AWS Cloud Formation stack is deleted.
- C. Define a deletion policy of type Retain forthe Amazon RDS resource to assure that the RDS database is not deleted with theAWS Cloud Formation stack.
- D. Define a deletion policy of type Snapshotfor the Amazon RDS resource to assure that the RDS database can be restoredafter the AWS Cloud Formation stack is deleted.
- E. Defineautomated backups with a backup retention period of 30 days for the Amazon RDSdatabase and perform point-in-time recovery of the database after the AWS CloudFormation stack is deleted.
Answer: CD
Explanation:
With the Deletion Policy attribute you can preserve or (in some cases) backup a resource when its stack is deleted. You specify a DeletionPolicy attribute for each resource that you want to control. If a resource has no DeletionPolicy attribute, AWS Cloud Formation deletes the resource by default.
To keep a resource when its stack is deleted, specify Retain for that resource. You can use retain for any resource. For example, you can retain a nested stack, S3 bucket, or CC2 instance so that you can continue to use or modify those resources after you delete their stacks.
For more information on Deletion policy, please visit the below url http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/aws-attri bute- deletionpolicy.html
NEW QUESTION 5
A company is running three production web server reserved EC2 instances with EBS-backed root volumes. These instances have a consistent CPU load of 80%. Traffic is being distributed to these instances by an Elastic Load Balancer. They also have production and development Multi-AZ RDS MySQL databases. What recommendation would you make to reduce cost in this environment without affecting availability of mission-critical systems? Choose the correct answer from the options given below
- A. Considerusing on-demand instances instead of reserved EC2 instances
- B. Considernot using a Multi-AZ RDS deployment for the development database
- C. Considerusing spot instances instead of reserved EC2 instances
- D. Considerremovingthe Elastic Load Balancer
Answer: B
Explanation:
Multi-AZ databases is better for production environments rather than for development environments, so you can reduce costs by not using this for development environments Amazon RDS Multi-AZ deployments provide enhanced availability and durability for Database (DB) Instances, making them a natural fit for production database workloads. When you provision a Multi- AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronously replicates the data to a standby instance in a different Availability Zone (AZ). Cach AZ runs on its own physically distinct, independent infrastructure, and is engineered to be highly reliable.
In case of an infrastructure failure, Amazon RDS performs an automatic failover to the standby (or to a read replica in the case of Amazon Aurora), so that you can resume database operations as soon as the failover is complete. Since the endpoint for your DB Instance remains the same after a failover, your application can resume database operation without the need for manual administrative intervention
For more information on Multi-AZ RDS, please refer to the below link: https://aws.amazon.com/rds/details/multi-az/
NEW QUESTION 6
Which of the below services can be used to deploy application code content stored in Amazon S3 buckets, GitHub repositories, or Bitbucket repositories
- A. CodeCommit
- B. CodeDeploy
- C. S3Lifecycles
- D. Route53
Answer: B
Explanation:
The AWS documentation mentions
AWS CodeDeploy is a deployment service that automates application deployments to Amazon EC2 instances or on-premises instances in your own facility.
For more information on Code Deploy please refer to the below link:
• http://docs.ws.amazon.com/codedeploy/latest/userguide/welcome.html
NEW QUESTION 7
When thinking of AWS Elastic Beanstalk's model, which is true?
- A. Applications have many deployments, deployments have many environments.
- B. Environments have many applications, applications have many deployments.
- C. Applications have many environments, environments have many deployments.
- D. Deployments have many environments, environments have many applications.
Answer: C
Explanation:
The first step in using Elastic Beanstalk is to create an application, which represents your web application in AWS. In Elastic Beanstalk an application serves as a
container for the environments that run your web app, and versions of your web app's source code, saved configurations, logs and other artifacts that you create
while using Elastic Beanstalk.
For more information on Applications, please refer to the below link: http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/applications.html
Deploying a new version of your application to an environment is typically a fairly quick process. The new source bundle is deployed to an instance and extracted, and the the web container or application server picks up the new version and restarts if necessary. During deployment, your application might still become unavailable to users for a few seconds. You can prevent this by configuring your environment to use rolling deployments to deploy the new version to instances in batches. For more information on deployment, please refer to the below link: http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/using-features.de ploy-existing-version, html
NEW QUESTION 8
You have a requirement to automate the creation of EBS Snapshots. Which of the following can be
used to achieve this in the best way possible?
- A. Createa powershell script which uses the AWS CLI to get the volumes and then run thescript as a cron job.
- B. Usethe A WSConf ig service to create a snapshot of the AWS Volumes
- C. Usethe AWS CodeDeploy service to create a snapshot of the AWS Volumes
- D. UseCloudwatch Events to trigger the snapshots of EBS Volumes
Answer: D
Explanation:
The best is to use the inbuilt sen/ice from Cloudwatch, as Cloud watch Events to automate the creation of CBS Snapshots. With Option A, you would be restricted to
running the powrshell script on Windows machines and maintaining the script itself And then you have the overhead of having a separate instance just to run that script.
When you go to Cloudwatch events, you can use the Target as EC2 CreateSnapshot API call as shown below.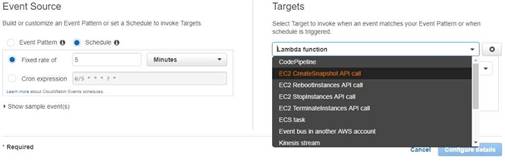
The AWS Documentation mentions
Amazon Cloud Watch Cvents delivers a near real-time stream of system events that describe changes in Amazon Web Services (AWS) resources. Using simple rules that you can quickly set up, you can match events and route them to one or more target functions or streams. Cloud Watch Cvents becomes aware of operational changes as they occur. Cloud Watch Cvents responds to these operational changes and takes corrective action as necessary, by sending messages to respond to the environment, activating functions, making changes, and capturing state information.
For more information on Cloud watch Cvents, please visit the below U RL:
• http://docs.aws.amazon.com/AmazonCloudWatch/latest/events/WhatlsCloudWatchCvents.htmI
NEW QUESTION 9
You have a setup in AWS which consists of EC2 Instances sitting behind and ELB. The launching and termination of the Instances are controlled via an Autoscaling Group. The architecture consists of a MySQL AWS RDS database. Which of the following can be used to induce one more step towards a self-healing architecture for this design?
- A. EnableReadReplica'sfortheAWSRDSdatabase.
- B. EnableMulti-AZ feature for the AWS RDS database.
- C. Createone more ELB in another region forfault tolerance
- D. Createone more Autoscaling Group in another region forfault tolerance
Answer: B
Explanation:
The AWS documentation mentions the following
Amazon RDS Multi-AZ deployments provide enhanced availability and durability for Database (DB) Instances, making them a natural fit for production database workloads. When you provision a Multi- AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronously replicates the data to a standby instance in a different Availability Zone (AZ). Cach AZ runs on its own physically distinct, independent infrastructure, and is engineered to be highly reliable.
In case of an infrastructure failure, Amazon RDS performs an automatic failover to the standby (or to a read replica in the case of Amazon Aurora), so that you can resume database operations as soon as the failover is complete. Since the endpoint for your DB Instance remains the same after a failover, your application can resume database operation without the need for manual administrative intervention.
For more information on AWS RDS Multi-AZ, please refer to the below link:
◆ https://aws.amazon.com/rds/details/multi-az/
NEW QUESTION 10
You need to scale an RDS deployment. You are operating at 10% writes and 90% reads, based on your logging. How best can you scale this in a simple way?
- A. Create a second master RDS instance and peer the RDS groups.
- B. Cache all the database responses on the read side with CloudFront.
- C. Create read replicas for RDS since the load is mostly reads.
- D. Create a Multi-AZ RDS installs and route read traffic to standby.
Answer: C
Explanation:
Amazon RDS Read Replicas provide enhanced performance and durability for database (DB) instances. This replication feature makes it easy to elastically scale out beyond the capacity constraints of a single DB Instance for read-heavy database workloads. You can create one or more replicas of a given source DB Instance and serve high-volume application read traffic from multiple copies of your data, thereby increasing aggregate read throughput. Read replicas can also be promoted when needed to become standalone DB instances.
Option A is invalid because you would need to maintain the synchronization yourself with a secondary instance.
Option B is invalid because you are introducing another layer unnecessarily when you already have read replica's Option D is invalid because you only use this for Standy's
For more information on Read Replica's, please refer to the below link: https://aws.amazon.com/rds/details/read-replicas/
NEW QUESTION 11
Which of these is not an instrinsic function in AWS CloudFormation?
- A. Fn::Equals
- B. Fn::lf
- C. Fn::Not
- D. Fn::Parse
Answer: D
Explanation:
You can use intrinsic functions, such as Fn::lf, Fn::Cquals, and Fn::Not, to conditionally create stack resources. These conditions are evaluated based on input parameters that you declare when you create or update a stack. After you define all your conditions, you can associate them with resources or resource properties in the Resources and Outputs sections of a template.
For more information on Cloud Formation template functions, please refer to the URL:
• http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/intrinsic-function- reference.html and
• http://docs.aws.a mazon.com/AWSCIoudFormation/latest/UserGuide/intri nsic-function- reference-conditions.html
NEW QUESTION 12
Your company has multiple applications running on AWS. Your company wants to develop a tool that notifies on-call teams immediately via email when an alarm is triggered in your environment. You have multiple on-call teams that work different shifts, and the tool should handle notifying the correct teams at the correct times. How should you implement this solution?
- A. Create an Amazon SNS topic and an Amazon SQS queu
- B. Configure the Amazon SQS queue as a subscriber to the Amazon SNS topic.Configure CloudWatch alarms to notify this topic when an alarm is triggere
- C. Create an Amazon EC2 Auto Scaling group with both minimum and desired Instances configured to 0. Worker nodes in thisgroup spawn when messages are added to the queu
- D. Workers then use Amazon Simple Email Service to send messages to your on call teams.
- E. Create an Amazon SNS topic and configure your on-call team email addresses as subscriber
- F. Use the AWS SDK tools to integrate your application with Amazon SNS and send messages to this new topi
- G. Notifications will be sent to on-call users when a CloudWatch alarm is triggered.
- H. Create an Amazon SNS topic and configure your on-call team email addresses as subscriber
- I. Create a secondary Amazon SNS topic for alarms and configure your CloudWatch alarms to notify this topic when triggere
- J. Create an HTTP subscriber to this topic that notifies your application via HTTP POST when an alarm is triggere
- K. Use the AWS SDK tools to integrate your application with Amazon SNS and send messages to the first topic so that on-call engineers receive alerts.
- L. Create an Amazon SNS topic for each on-call group, and configure each of these with the team member emails as subscriber
- M. Create another Amazon SNS topic and configure your CloudWatch alarms to notify this topic when triggere
- N. Create an HTTP subscriber to this topic that notifies your application via HTTP POST when an alarm is triggere
- O. Use the AWS SDK tools to integrate your application with Amazon SNS and send messages to the correct team topic when on shift.
Answer: D
Explanation:
Option D fulfils all the requirements
1) First is to create a SNS topic for each group so that the required members get the email addresses.
2) Ensure the application uses the HTTPS endpoint and the SDK to publish messages Option A is invalid because the SQS service is not required.
Option B and C are incorrect. As per the requirement we need to provide notification to only those on-call teams who are working in that particular shift when an alarm is triggered. It need not have to be send to all the on-call teams of the company. With Option B & C, since we are not configuring the SNS topic for each on call team the notifications will be send to all the on-call teams. Hence these 2 options are invalid. For more information on setting up notifications, please refer to the below document link: from AWS http://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/US_SetupSNS.html
NEW QUESTION 13
You have decided that you need to change the instance type of your production instances which are running as part of an AutoScaling group. The entire architecture is deployed using CloudFormation Template. You currently have 4 instances in Production. You cannot have any interruption in service and need to ensure 2 instances are always runningduring the update? Which of the options below listed can be used for this?
- A. AutoScalingRollingUpdate
- B. AutoScalingScheduledAction
- C. AutoScalingReplacingUpdate
- D. AutoScalinglntegrationUpdate
Answer: A
Explanation:
The AWS::AutoScaling::AutoScalingGroup resource supports an UpdatePoIicy attribute. This is used to define how an Auto Scalinggroup resource is updated when an update to the Cloud Formation stack occurs. A common approach to updating an Auto Scaling group is to perform a rolling update, which is done by specifying the AutoScalingRollingUpdate policy. This retains the same Auto Scaling group and replaces old instances with new ones, according to the parameters specified. For more information on Autoscaling updates, please refer to the below link: https://aws.amazon.com/premiumsupport/knowledge-center/auto-scaling-group-rolling-updates/
NEW QUESTION 14
You need to monitor specific metrics from your application and send real-time alerts to your Devops Engineer. Which of the below services will fulfil this requirement? Choose two answers
- A. Amazon CloudWatch
- B. Amazon Simple Notification Service
- C. Amazon Simple Queue Service
- D. Amazon Simple Email Service
Answer: AB
Explanation:
Amazon Cloud Watch monitors your Amazon Web Services (AWS) resources and the applications you run on AWS in real time. You can use Cloud Watch to collect and track metrics, which are variables you can measure for your resources and applications. Cloud Watch alarms send notifications or automatically make changes to the resources you are monitoring based on rules that you define.
For more information on AWS Cloudwatch, please refer to the below document link: from AWS
• http://docs.aws.a mazon.com/AmazonCloudWatch/latest/monitoring/WhatlsCloud Watch.htm I Amazon Cloud Watch uses Amazon SNS to send email. First, create and subscribe to an SNS topic.
When you create a CloudWatch alarm, you can add this SNS topic to send an email notification when the alarm changes state
For more information on AWS Cloudwatch and SNS, please refer to the below document link: from AWS
http://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/US_SetupSNS.html
NEW QUESTION 15
Your CTO has asked you to make sure that you know what all users of your AWS account are doing to change resources at all times. She wants a report of who is doing what over time, reported to her once per week, for as broad a resource type group as possible. How should you do this?
- A. Create a global AWS CloudTrail Trai
- B. Configure a script to aggregate the log data delivered to S3 once per week and deliver this to the CTO.
- C. Use CloudWatch Events Rules with an SNS topic subscribed to all AWS API call
- D. Subscribe the CTO to an email type delivery on this SNS Topic.
- E. Use AWS 1AM credential reports to deliver a CSV of all uses of 1AM UserTokens overtime to the CTO.
- F. Use AWS Config with an SNS subscription on a Lambda, and insert these changes over time into a DynamoDB tabl
- G. Generate reports based on the contents of this table.
Answer: A
Explanation:
AWS CloudTrail is an AWS service that helps you enable governance, compliance, and operational and risk auditing of your AWS account. Actions taken by a user, role, or an AWS service are recorded as events in CloudTrail. Events include actions taken in the AWS Management Console, AWS Command Line Interface, and AWS SDKs and APIs.
Visibility into your AWS account activity is a key aspect of security and operational best practices. You can use CloudTrail to view, search, download, archive, analyze, and respond to account activity across your AWS infrastructure. You can identify who or what took which action, what resources were acted upon, when the event occurred, and other details to help you analyze and respond to activity in your AWS account.
For more information on Cloudtrail, please visit the below URL:
• http://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-user-guide.html
NEW QUESTION 16
In reviewing the Auto-Scaling events for your application you notice that your application is scaling up and down multiple times in the same hour. What design choice could you make to optimize for costs while preserving elasticity?
Choose 2 options from the choices given below
- A. Modifythe Auto Scaling policy to use scheduled scaling actions
- B. Modifythe Auto Scaling Group cool down timers
- C. Modifythe Amazon Cloudwatch alarm period that triggers your AutoScaling scale downpolicy.
- D. Modifythe Auto Scalinggroup termination policy to terminate the newest instancefirst.
Answer: BC
Explanation:
The Auto Scaling cooldown period is a configurable setting for your Auto Scalinggroup that helps to ensure that Auto Scaling doesn't launch or terminate additional instances before the previous scaling activity takes effect. After the Auto Scalinggroup dynamically scales using a simple scaling policy. Auto Scaling waits for the cooldown period to complete before resuming scaling activities. When you manually scale your Auto Scaling group, the default is not to wait for the cooldown period,
but you can override the default and honor the cooldown period. Note that if an instance becomes
unhealthy. Auto Scaling does not wait for the cooldown period to complete before replacing the unhealthy instance.
For more information on Autoscale cool down timers please visit the URL: http://docs.ws.amazon.com/autoscaling/latest/userguide/Cooldown.htm I
You can also modify the Cloudwatch triggers to ensure the thresholds are appropriate for the scale down policy For more information on Autoscaling user guide please visit the URL: http://docs.aws.amazon.com/autoscaling/latest/userguide/as-scale-based-on-demand.html
NEW QUESTION 17
You need to deploy a multi-container Docker environment on to Elastic beanstalk. Which of the following files can be used to deploy a set of Docker containers to Elastic beanstalk
- A. Dockerfile
- B. DockerMultifile
- C. Dockerrun.aws.json
- D. Dockerrun
Answer: C
Explanation:
The AWS Documentation specifies
A Dockerrun.aws.json file is an Clastic Beanstalk-specific JSON file that describes how to deploy a set of Docker containers as an Clastic Beanstalk application. You can use aDockerrun.aws.json file for a multicontainer Docker environment.
Dockerrun.aws.json describes the containers to deploy to each container instance in the environment as well as the data volumes to create on the host instance for the containers to mount.
For more information on this, please visit the below URL:
http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/create_deploy_docker_v2config.html
NEW QUESTION 18
For AWS Auto Scaling, what is the first transition state an existing instance enters after leaving Standby state?
- A. Detaching
- B. Terminating:Wait
- C. Pending
- D. EnteringStandby
Answer: C
Explanation:
The below diagram shows the Lifecycle policy. When the stand-by state is exited, the next state is pending.
For more information on Autoscaling Lifecycle, please refer to the below link: http://docs.aws.amazon.com/autoscaling/latest/userguide/AutoScaingGroupLifecycle.html
NEW QUESTION 19
What is the amount of time that Opswork stacks services waits for a response from an underlying instance before deeming it as a failed instance?
- A. Iminute.
- B. 5minutes.
- C. 20minutes.
- D. 60minutes
Answer: B
Explanation:
The AWS Documentation mentions
Every instance has an AWS OpsWorks Stacks agent that communicates regularly with the service. AWS OpsWorks Stacks uses that communication to monitor instance health. If an agent does not communicate with the service for more than approximately five minutes, AWS OpsWorks Stacks considers the instance to have failed.
For more information on the Auto healing feature, please visit the below URL: http://docs.aws.amazon.com/opsworks/latest/userguide/workinginstances-auto healing.htmI
NEW QUESTION 20
You have been tasked with deploying a scalable distributed system using AWS OpsWorks. Your distributed system is required to scale on demand. As it is distributed, each node must hold a configuration file that includes the hostnames of the other instances within the layer. How should you configure AWS OpsWorks to manage scaling this application dynamically?
- A. Create a Chef Recipe to update this configuration file, configure your AWS OpsWorks stack to use custom cookbooks, and assign this recipe to the Configure LifeCycle Event of the specific layer.
- B. Update this configuration file by writing a script to poll the AWS OpsWorks service API for new instance
- C. Configure your base AMI to execute this script on Operating System startup.
- D. Create a Chef Recipe to update this configuration file, configure your AWS OpsWorks stack to use custom cookbooks, and assign this recipe to execute when instances are launched.
- E. Configure your AWS OpsWorks layer to use the AWS-provided recipe for distributed host configuration, and configure the instance hostname and file path parameters in your recipes settings.
Answer: A
Explanation:
Please check the following AWS DOCs which provides details on the scenario. Check the example of "configure".
◆ https://docs.aws.amazon.com/opsworks/latest/userguide/workingcookbook-events.html You can use the Configure Lifecycle event
This event occurs on all of the stack's instances when one of the following occurs:
• An instance enters or leaves the online state.
• You associate an Elastic IP address with an instance or disassociate one from an instance.
• You attach an Elastic Load Balancing load balancer to a layer, or detach one from a layer. Ensure the Opswork layer uses a custom Cookbook
For more information on Opswork stacks, please refer to the below document link: from AWS
• http://docs.aws.a mazon.com/opsworks/latest/userguide/welcome_classic.html
NEW QUESTION 21
......
Thanks for reading the newest DOP-C01 exam dumps! We recommend you to try the PREMIUM Certshared DOP-C01 dumps in VCE and PDF here: https://www.certshared.com/exam/DOP-C01/ (116 Q&As Dumps)